Big Data With Hadoop
นิยามของคำว่า Big Data คือ ข้อมูลขนาดใหญ่มหาศาลมากจนซอฟต์แวร์นั้นไม่สามารถที่จะจัดการหรือวิเคราะห์ได้อย่างมีประสิทธิภาพ หรือไม่สามารถวิเคราะห์ได้ทันในเวลาที่ต้องการแล้ว แม้จะปรับแต่งซอฟต์แวร์หรือเพิ่มฮาร์ดแวร์จนไม่สามารถขยายได้อีกแล้ว จึงต้องหาวิธีการใหม่ในการวิเคราะห์ประมวลผลข้อมูลนั้นให้ทันตามเวลาที่ต้องการ
ข้อมูลที่เก็บที่จะเรียกว่าเป็น Big Data ต้องมีคุณสมบัติ อย่างน้อย 3 ข้อ ดังนี้
- Volume - ข้อมูลมีขนาดใหญ่และมีการเติบโตของข้อมูลที่รวดเร็ว
- Velocity - ข้อมูลมีการเปลี่ยนแปลงอย่างรวดเร็ว เช่น ข้อมูลจาก Social Media หรือข้อมูลจาก Sensor ต่าง ๆ ที่ส่งเข้ามา transaction log การใช้งานต่าง ๆ
- Variety - ข้อมูลมีความหลายหลายทั้งข้อมูลที่เป็น Structure และ Unstructure เช่น ข้อมูล json, csv file, database รูปภาพ เป็นต้น

What is Hadoop ?
Hadoop เป็นซอฟต์แวร์ ตัวหนึ่งที่นิยมนำมาใช้ในการทำ Big Data เนื่องจาก Hadoop นั้นเป็น Open Source Technology สามารถที่จะพัฒนาต่อยอดได้ และมีเครื่องมือต่าง ๆ ที่สามารถมาเชื่อมต่อกับ Hadoop เพื่อใช้งานได้ เช่น Pig, Hive, Hbase เป็นต้น โดยใช้ Hardware PC หรือ Server ทั่วไปมาสร้างเป็น Hadoop Cluster ได้

จุดกำเนิดของ Hadoop
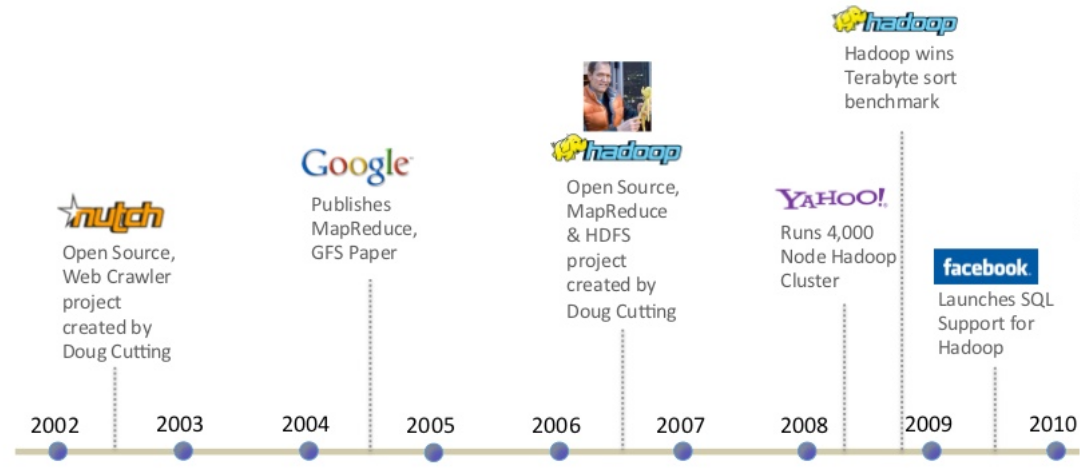
ในปี 2003-2004 กูเกิลได้ตีพิมพ์บทความทางวิชาการเรื่อง The google File System และ MapReduce: Simplified Data Processing on Large Clusters ซี่งเป็นบทความวิธีการจัดเก็บข้อมูลขนาดใหญ่และ วิธีการประมวลผลข้อมูลขนาดใหญ่ โดยการใช้การประมวลผลแบบขนานโดยใช้เครื่องคอมพิวเตอร์หลาย ๆ เครื่องช่วยกันประมวลผล ในตอนนั้น คุณ Douglass Read Cutting (Doug Cutting) ซึ่งในขณะนั้นเป็นพนักงานของ Yahoo มีความสนใจในงานตีพิมพ์นี้ จึงได้ทำการสร้างซอฟต์แวร์ที่อิงกับคอนเซปต์ของบทความดังกล่าว ซึ่งได้ตั้งชื่อซอฟต์แวร์ที่่สร้างขึ้นว่า Hadoop โดยชื่อ Hadoop มาจากชื่อตุ๊กตาช้างของลูกชาย และเผยแพร่ซอฟต์แวร์ Hadoop ออกมาในรูปแบบ Open Source
ส่วนประกอบของ Hadoop
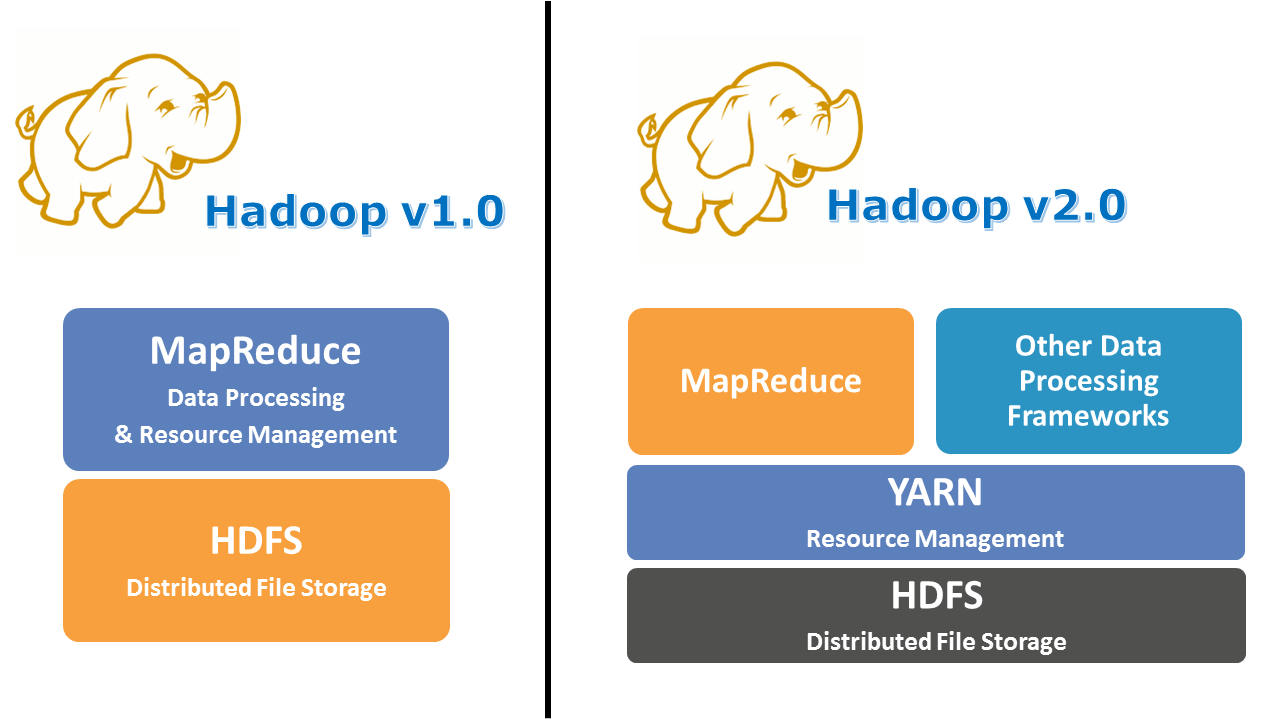
ถ้าพูดถึง Hadoop นั้น ในตัวของ Hadoop เองจะประกอบไปด้วย 2 ส่วนหลัก ๆ คือ
- Hadoop Distrubuted File System(HDFS) - จะเป็นส่วนเก็บข้อมูลของระบบ Hadoop โดยมีเครื่องมือจัดการไฟล์แบบกระจายที่ชื่อ HDFS (Hadoop Distribute File System) คอยช่วยจัดการให้ โดย User จะเห็นพื้นที่ในการจัดเก็บไฟล์เป็นพื้นที่เดียวกัน โดยใช้หลักการในการจับเก็บไฟล์โดยการหั่นไฟล์ออกเป็นชิ้นเล็ก ๆ และกระจายไปจัดเก็บในหลาย ๆ เครื่อง พร้อมทำ replication ข้อมูลเพื่อป้องกันการสูญหายของข้อมูลในกรณีที่มีเครื่องในคลัสเตอร์ตาย ข้อมูลจะยังมีสำเนาอยู่ในเครื่องอื่น ๆ
- Map-Reduce - จะป็นส่วนในการประมวลผลข้อมูลที่เก็บอยู่บน HDFS
- Yarn (yet another resource negotiator) - เป็นเครื่องมือที่เพิ่มเข้ามาใน Hadoop Version 2 โดยเป็นเครื่องมือที่เป็นตัวกลางในการเชื่อมต่อกับเครื่องมืออื่น ๆ ที่จะเข้ามาใช้งาน Hadoop
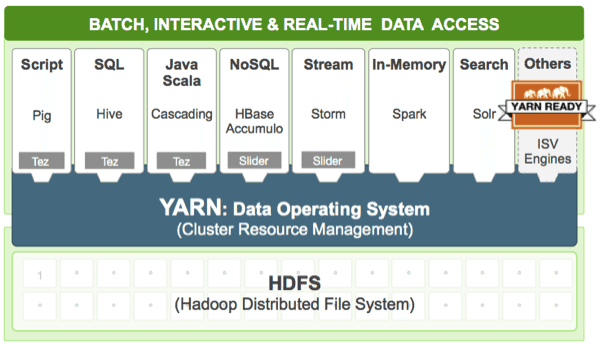
Hadoop Distribution
เป็นการนำ Aapache Hadoop มารวบรวมกับเครื่องมือต่าง ๆ ที่แวดล้อม Hadoop ซึ่งแต่ละค่ายก็จะรวบรวม Tool ต่าง ๆ กัน และมีตัวช่วยติดตั้งระบบ Hadoop เพื่อให้ติดตั้งง่ายขึ้น และสามารถ Monitoring ผ่านซอฟต์แวร์ พร้อมขาย Support/Subscription หากองค์การต้องการได้ด้วย
Hadoop Distribution ที่นิยมในปัจจุบัน
- Cloudera
- Hortonworks
- MapR

ณ. ปัจจุบัน Cloudera และ Hortonworks ได้ประกาศควบรวมกิจการกันเรียบร้อยแล้ว โดยทั้งสองบริษัทจะรวมอยู่ภายใต้ชื่อของ Cloudera
ผลงานที่ผ่านมา
- สำนักงานพัฒนาเทคโนโลยีอวกาศและภูมิสารสนเทศ (องค์การมหาชน)
- สำนักงานปลัดกระทรวงสาธารณสุข
- สำนักงานป้องกันและปราบปรามการฟอกเงิน